- Home
- Faculty Members
- Department of Management and Information Sciences
- Koichi Tanigaki
Faculty of Environmental and Information Sciences
Department of Management and Information Sciences
- Key words
- Natural language processing, lexical semantics, language model, text generation

Ph.D. (Science in Global Information and Telecommunication Studies) / Professor
Koichi Tanigaki
Education
Department of Information Engineering, faculty of engineering, Tohoku university. Graduate school of information science, Tohoku university, master's program.
Graduate school of global information and telecommunication studies, Waseda university, doctoral program.
Professional Background
Information technology R&D center, Mitsubishi electric corporation, head researcher.
Advanced telecommunication research institute international, researcher.
Consultations, Lectures, and Collaborative Research Themes
Joint research and technical consultation on utilizing big data such as accumulated documents, information system logs, etc., whose quantification/aggregation is not trivial.
Main research themes and their characteristics
「Neural text generation in multiple context」
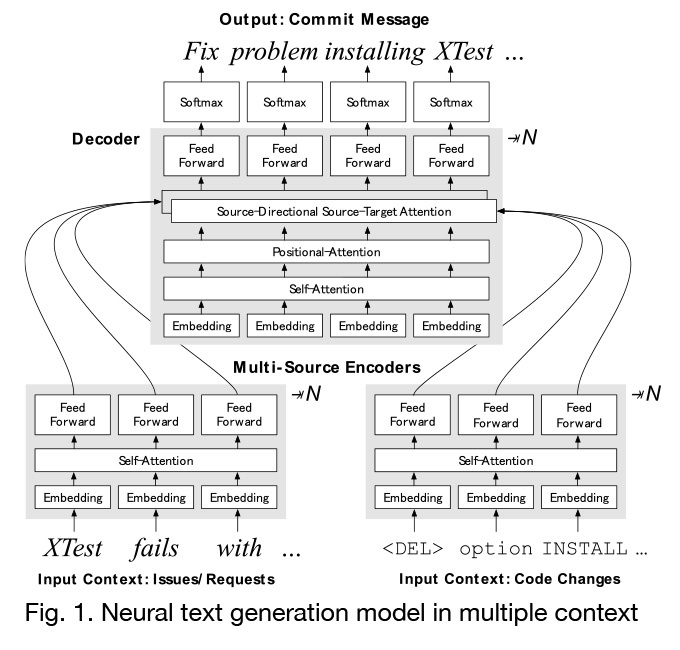
Experts such as doctors and engineers spend a lot of effort for writing business reports of diagnosis and treatment, which must be submitted for business purposes. Writing reports is a heavy-duty tasks for busy experts, and its automation is eagerly desired. As an first target for experimental studies, we studied neural text generation of source code modification reports (commit messages).
To compose useful explanations, messages should include brief summary of the code modification (= first context), as well as the reason of the modification (= second context: relationship with functional improvement request or bug reports). In the previous researches, explanation sentences are generated by simply applying a machine translation for single input context (code modification), which had a problem that it could not generate sufficient explanation on the reason of modification.
We proposed a multi-encoder neural network model (Fig. 1) that simultaneously inputs multiple contexts with different properties and uses the attention mechanism to dynamically switch the contexts to be referenced. Experimental results using 180,000 data from an Internet repository service confirms the effect of the proposed model.
「Hierarchical Bayesian model of word sense and metaphor recognition」
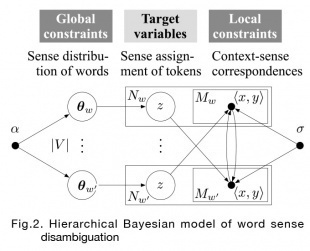
Human's rich and smooth verbal communication is often colored by metaphors, where words are expected to be interpreted in a leap from its literal meanings. Future AI applications such as dialogue robots are required to accurately recognize metaphors so as to function properly and smoothly in our living space. Among the metaphors, recognizing ideomatic metaphors, which is conventionally used, constitutes a part of the word sense disambiguation problem and has been tackled as a long-standing task in natural language processing.
We proposed an unsupervised model for all-words word sense disambiguation (WSD) to cope with the enormous number of sense classes inherent in the task. The proposed model is a hierarchical Bayesian model (Fig. 2) that incorporates two types of soft constraints and infers natural correspondence between unlabeled word occurrences and numerous senses: 1) senses of word instances follow the prior distribution of each word-type, 2) senses in a context follow the extrapolation from other words' senses in similar context. Experimental results applied to a standard benchmark dataset confirmed the advantages of our hierarchical model.
Major academic publications
Tanigaki, K., Munaka, T. and Sagisaka, Y.: Hierarchical Bayesian mapping of word occurrences and word senses for unsupervised sense disambiguation, IPSJ Journal, Vol. 57, No. 8, pp. 1--11 (2016).
Tanigaki, K., Munaka, T. and Sagisaka, Y.: Density maximization of context-to-sense mapping for unsupervised word sense disambiguation, IPSJ Journal, Vol. 57, No. 3, pp. 1--11 (2016).
Tanigaki, K., Shiba, M., Munaka, T. and Sagisaka, Y.: Density Maximization in Context-Sense Metric Space for All-words WSD, Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL2013), Vol. 1, pp. 884–893 (2013).