Faculty of Engineering
Department of Electrical and Electronic Engineering
- Key words
- Artificial Intelligence, Machine Learning, Deep Learning, Neural Network, Social Media, Text Mining, Natural Language Processing, Data Science

Doctor (Engineering) / Professor
Ikuo Keshi
Education
Osaka University, Faculty of Engineering, Electronic Engineering
Osaka University, Graduate School of Engineering, Electronic Engineering Master's Course
Nara Institute of Science and Technology, Division of Information Science, Doctor's Course
Professional Background
Sharp Corporation , e-Life Department General Manager/Chief Technical Research Fellow
Artificial Intelligence Laboratory of Massachusetts Institute of Technology, Visiting Scientist
Nara Institute of Science and Technology, Part-time lecturer
Consultations, Lectures, and Collaborative Research Themes
Joint research on ”AI × marketing” (regional and industrial promotion) such as SNS analysis.
Lecture and technical consultation on “The Future Brought to You by AI & IoT”
Main research themes and their characteristics
「Semantically Readable Distributed Representation Learning and Its Expandability Using a Word Semantic Vector Dictionary」
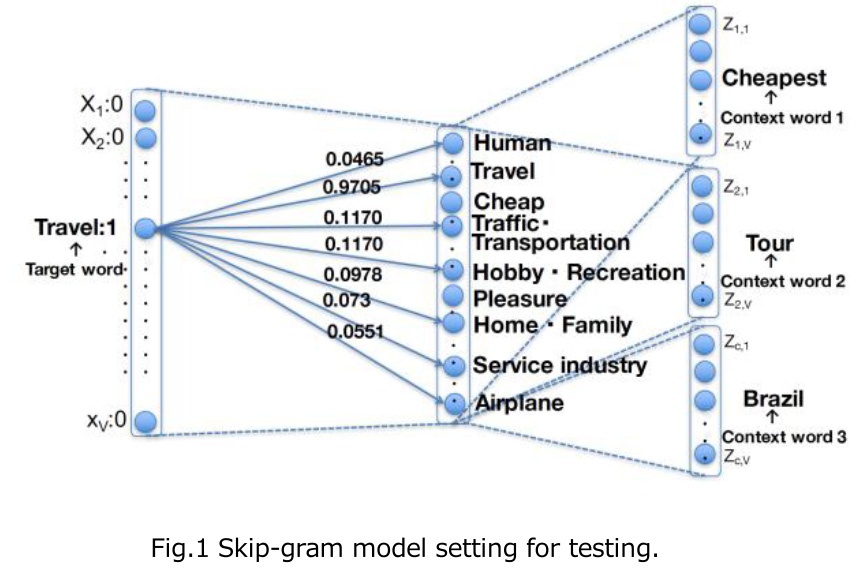
The problem with distributed representations generated by neural networks is that the meaning of the features is difficult to understand. We propose a new method that gives a specific meaning to each node of a hidden layer by introducing a manually created word semantic vector dictionary into the initial weights and by using paragraph vector models (Fig.1). Our experimental results demonstrated that the learned vector is better than the performance of the existing paragraph vector in the evaluation of the Twitter sentiment analysis task using the single domain benchmark. Also, we determined the readability of document embeddings, which means distributed representations of documents, in a user test. The definition of readability in this paper is that people can understand the meaning of large weighted features of distributed representations. A total of 52.4% of the top five weighted hidden nodes were related to tweets where one of the paragraph vector models learned the document embeddings. For the expandability evaluation of the method, we improved the dictionary based on the results of the hypothesis test and examined the relationship of the readability of learned word vectors and the task accuracy of Twitter sentiment analysis using the diverse and large-scale benchmark. We also conducted a word similarity task using the Wikipedia corpus to test the domain-independence of the method. We found the expandability results of the method are better than or comparable to the performance of the paragraph vector. Also, the objective and subjective evaluation support each hidden node maintaining a specific meaning. Thus, the proposed method succeeded in improving readability.
「Reputation Information Extraction from Twitter Using a Word Semantic Vector Dictionary」

Distributed representations named word2vec and paragraph vectors, computed using simple neural networks, have been widely used. Paragraph vectors achieved state-of-the-art results on sentiment analysis. The practical problem is that a large collection of documents is required for overcoming the sparsity of words. This paper proposes a method for introducing manually-created word semantic vectors for solving the problem. The word semantic vector dictionary consists of about 20,000 words, which are given the relationship with 266 feature words. We proposed the integration method of the manually-created word semantic vectors with paragraph vectors and applied it for the reputation information extraction from Twitter (Fig.2). The proposed method indicated a macro average F-score of 71.9 for positive and negative prediction in the 3-class classifications of positive, neutral, and negative in the benchmark of a specific smartphone product brand, which consists of about 12,000 tweets. The method exceeds the macro average F-score of the conventional method, paragraph vectors, by 3.2 points. Also, the method can perform error analysis using expanded feature words. Moreover, its effectiveness is larger even if a minimum benchmark consisting of a variety of products exists.
Major academic publications
I. Keshi, Y. Suzuki, K. Yoshino, and S. Nakamura
“Semantically Readable Distributed Representation Learning and Its Expandability Using a Word Semantic Vector Dictionary”
IEICE Trans. on Information and Systems, Vol.E101-D, No.4, pp.1066 – 1078, April 2018.
I. Keshi, Y. Suzuki, K. Yoshino, G. Neubig, K. Ohara, T. Mukai, and S. Nakamura
“Reputation Information Extraction from Twitter Using a Word Semantic Vector Dictionary (in Japanese)”
IEICE Trans. on Information and Systems (Japanese Edition), Vol.J100-D, No.4, pp.530 - 543, April 2017.
I. Keshi, H. Ikeuchi, K. Kuromusha
“Associative image retrieval using knowledge in encyclopedia text”
SYSTEMS AND COMPUTERS IN JAPAN 27(12), pp.53 – 62, Nov. 1996.